Wissenschaftliches Rechnen


Wissenschaftliches Rechnen am MPI für Bildungsforschung
Am Max-Planck-Institut für Bildungsforschung haben Wissenschaftler*innen die Möglichkeit, ihre Forschungsdaten und Modelle mit unterschiedlichen Methoden und unter Zuhilfenahme der hiesigen Rechnerarchitektur auszuwerten. Neben der Berechnung und Analyse von Modellen am Arbeitsplatz ist es möglich, außerhalb des Instituts über den Citrix-Zugang auf diverse Programme zuzugreifen. Komplexere Modelle können ebenfalls vom Arbeitsplatz vor Ort oder über eine verschlüsselte Verbindung über die Rechencluster des Instituts ausgewertet werden.
Vorgehensweisen/ Methoden
Sequentielles Rechnen
Für die Nutzung von sequentiellen Rechenmodellen können sich die Wissenschaftler*innen von ihren Arbeitsplatzrechnern über Remote Desktop mit einem Windowsserver verbinden. Dadurch wird ihnen die bekannte Windowsumgebung geboten, auf dem die Software genauso läuft, wie auf den Arbeitsplatzrechnern. Auf dem Server wird die Berechnung des Modells ohne vorherige Anpassung durchgeführt. Jeder Teilschritt des Modells wird nacheinander abgearbeitet, ohne dass Teilsegmente parallel berechnet werden können.
Arbeitsschritte:

- Download der Forschungsdaten von einem Dateiserver
- Sequenzielle bzw. serielle Berechnung des Modells
- Hochladen der Daten auf einen Dateiserver
Parallelisierung

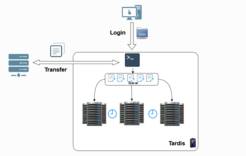
Diese Vorgehensweise erlaubt es den Wissenschaftler*innen, sich von Ihrem Laptop oder Arbeitsplatz aus mittels einer verschlüsselten Verbindung über SSH-Protokoll mit einem Knotenpunkt eines Rechenclusters (= tardis) zu verbinden. An diesem stehen ihnen alle Werkzeuge und Programme des Clusters zur Verfügung um ihr Modell für die Berechnung vorzubereiten und zu testen. Das Modell wird dabei so angepasst, dass die Gesamtaufgabe in Teilsegmente zerlegt wird, die unabhängig und deswegen parallel voneinander durchgeführt werden können. Nach dem diese Anpassung vollzogen wurde, wird das Modell in die Warteschleife mit Aufträgen eingereicht. Durch die Parallelisierung, ist die Berechnung eines Modells schneller und effizienter umsetzbar, gleichzeitig stehen dem Nutzer für die Berechnung mehr CPU-Kerne (Prozessorkerne) als bei der sequentiellen Berechnung zur Verfügung. Nachdem der Auftrag beendet wurde, können die Ergebnisse gespeichert und auf einem Dateiserver abgelegt werden.